🧠 What is a Vector Database? (Fun Analogy Edition)
It's like a giant library... but instead of books, each shelf stores feelings. Not titles. Not authors. Just vibes

🧠 Imagine This...
You're running a pet adoption center. Each pet (dog, cat, husky, etc.) has:
🐾 A name
🎨 A color
🧼 A fluffiness level
📸 A photo
🧬 And a unique vibe or personality you can’t quite describe in words...
But now a visitor walks in and says:
“I want a pet that feels like this one here” — and shows you a photo of a cat they saw on Instagram.
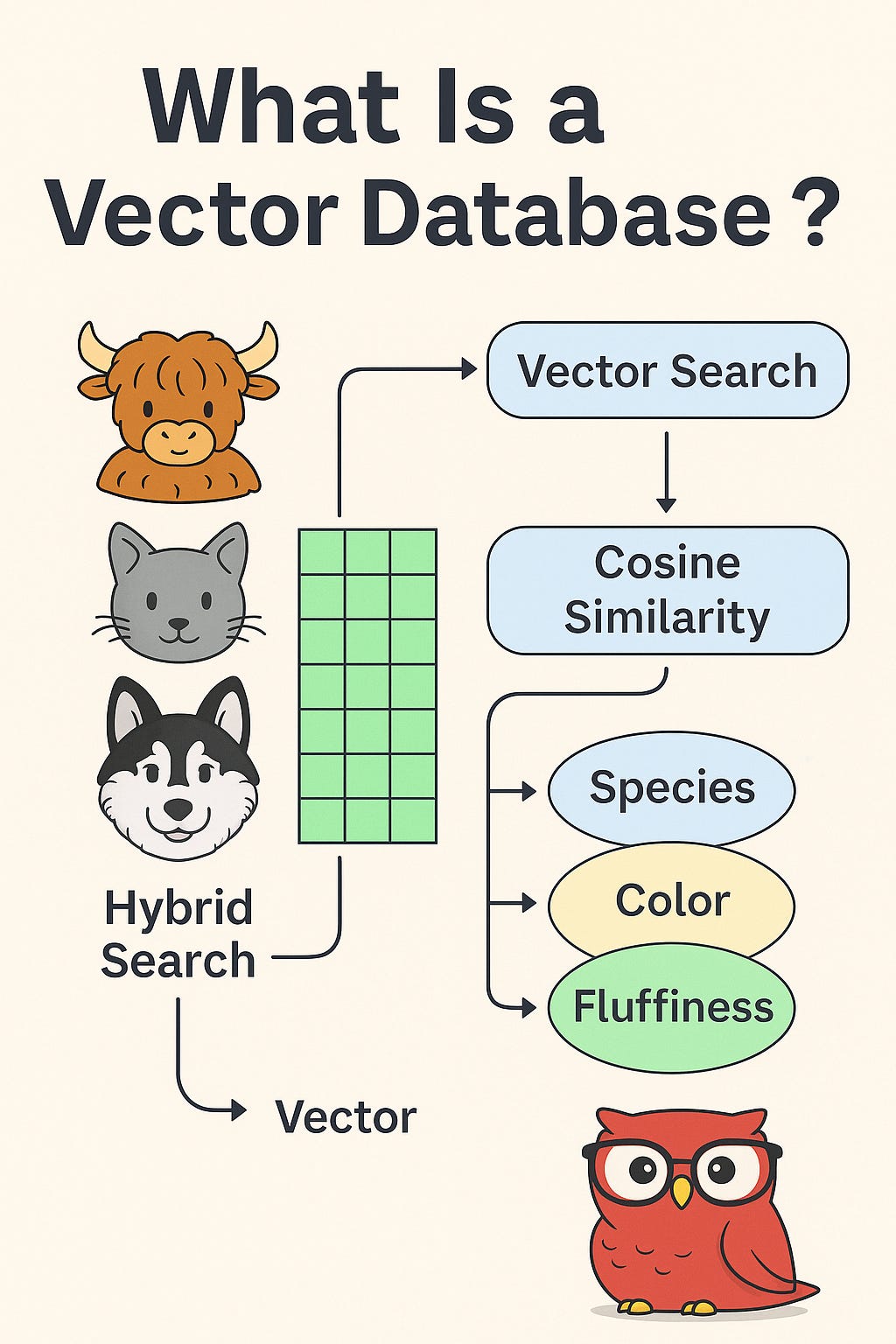
🧮 Here's What You Do
Convert the Instagram cat into a vector — a list of numbers that represent its vibe (like fluffiness, energy, size).
You look into your system (📦 a Vector Database) where all other pets have already been vectorized.
You compare that visitor’s vector to all stored vectors using:
🧠 Cosine similarity (How close are the vibes?)
📏 Euclidean distance (How far apart are they in this abstract space?)
You return the most similar pets instantly.
🔍 So What’s a Vector DB, Really?
It’s a super-smart catalog that stores:
Vectors: Those number representations of images, text, audio, etc.
Payloads: Extra info like pet names, URLs, tags, colors.
Search functions: To find what’s most similar to something else.
And it supports:
🤹 Hybrid search (mix keyword + semantic similarity)
🗂 Collections (organize into buckets)
🧩 Multitenancy (serve multiple apps/teams)
🛡️ RBAC (control who can see what)
🤖 Why Do AI Engineers Love It?
Because when your AI chatbot or assistant needs to "remember" things like:
Past conversations,
Uploaded documents,
FAQs or user manuals...
A vector database lets it search meaningfully, not just match exact keywords. It’s the memory behind modern AI apps.
🧬 TL;DR
A vector DB is like your brain's "vibe-matching" engine — it finds the most similar idea to what you're thinking about, even if you don’t say it perfectly.
🧬 So What are the Steps to Understand :
📚 Step 1: What’s a Vector?
A vector is just a list of numbers that represents meaning. Think of it as the "emotional fingerprint" of data.
🐶 “Dog” might be [0.9, 0.2, 0.4]
🐱 “Cat” might be [0.85, 0.3, 0.5]
🦄 “Unicorn” might be [0.1, 0.9, 0.95]
These aren’t random—they're learned by deep learning models trained to capture relationships like:
🐶 + 🐾 = 🐕
🧒 + 📚 = 🧑🎓
🏢 Step 2: What’s a Vector Database?
A vector database is like a Google search for meaning instead of words.
You ask: “Find me something like a cute small animal.”
It searches: “Which stored vectors are closest to this idea?”
How? By using Cosine Similarity, Euclidean Distance, or Dot Product to find the closest match.
🧲 Instead of keyword matching, it says:
“A fluffy 🐱 and a baby 🐰 are both emotionally similar to your request!”
🗂️ Step 3: What's Stored Inside?
Each record in a vector DB includes:
A vector → numerical essence of the item.
A payload → extra info like:
🧬 Species: Cat
🎨 Color: Orange
🌐 URL: instrovate.com/cute-cat.jpg
🛠️ Who Uses It?
Data Scientists: Upload embeddings from deep learning models.
Developers: Query using Python, TypeScript, or Go.
Apps: Build RAG pipelines that retrieve smart, relevant chunks using just a “vibe.”
🎯 Why It’s Powerful for RAG & AI Engineers
🔍 Enables semantic search ("meaning match", not exact words).
🧠 Forms the backbone of Retrieval-Augmented Generation (RAG).
⚡ Super fast — optimized for billions of records.
🧩 Supports metadata filtering, hybrid queries, and more.
💡 So next time someone asks you what a vector DB is, say:
“It's like searching through a giant emotion-indexed mind palace!”